
Written by: Kristjan Eljand | Technology Scout
Azure has just recently launched their new Machine Learning service that aims to be a central hub for carrying out all data science tasks. In this blog post, I’ll give a step-by-step introduction of the Designer module — a tool that enables us to prepare the data, train ML models and deploy them in drag-and-drop style. Our goal is to build a machine learning model for predicting whether the electricity consumption of the single household will be more than 22 kWh or less than 22 kWh.
1. About the data
Data download link. The data reflects a daily electricity consumption of a single household during the 1-year period of October 2018 — September 2019:
- date — the date of the consumption;
- month — month corresponding to the date;
- weekday — numbered from 1 to 7, starting with Monday;
- precipitation — rain/snowfall in mm during that date;
- temperature — the average temperature of that date;
- amount — the actual electricity consumption of the household in kWh;
- amount_-1d — the actual electricity consumption on the previous day;
- amount>22 — binary variable indicating whether the consumption was more than 22 kWh or less than 22 kWh. This will be our target column!

2. Prerequisites
2.1. Create a Microsoft Azure account
To start, you need an Azure subscription. You can create a new subscription or access existing subscription information from the Azure portal. At the time of writing, Azure gives you an initial free credit of $170 to try out the cloud services but you still need to insert your credit card data to create the account.
2.2. Create a Resource group
After you have logged in to Azure cloud, it is reasonable to start by creating a new Resource group. That way, we can delete all of the paid resources at once after we have finished our work. First, click on “Resource groups”.

Next, select “Add”

The form that opens, have the following fields:
- Subscription — should be pre-filled for you. In my example, it’s my E-Lab subscription.
- Resource group — enter the name for your resource group. I named it “ml-training”.
- Region — select the nearest region (West Europe in my case) — this is a server location for your resource group.

After filling the form, press “Review + create” and then again on “Create”. That’s it — you should now be able to find your freshly created resource group by its name.

2.3. Create a Resource
The Azure platform has a concept of resources which means a specific service. In order to create a Machine Learning resource use the search field on the top navigation bar. Search for “machine learning” and click on “Machine Learning”:
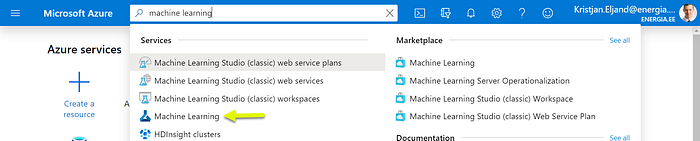
On the next page click “Add”:

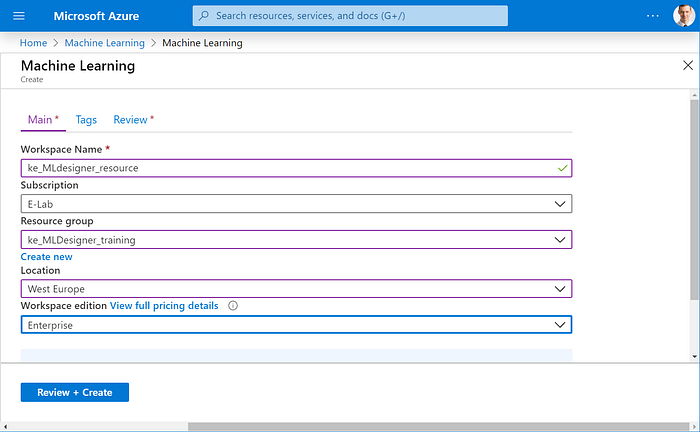
The form asks for the following information:
- Workspace name: Give a name to your service and remember it;
- Subscription: This should be prefilled for you;
- Resource group: Ask from IT admin or your manager what would be the correct resource group or enter a name to create a new resource group (A resource group holds related resources for an Azure solution).
- Location: choose the same location as you did with the resource group;
- Workspace edition: NB: Select “Enterprise” — ML through the web interface is only available in Enterprise edition!
- Click “Review + Create” -> you will be directed to a Review page. If everything is correct, click “Create” and Azure will create all the resources that are needed for Machine Learning workspace.
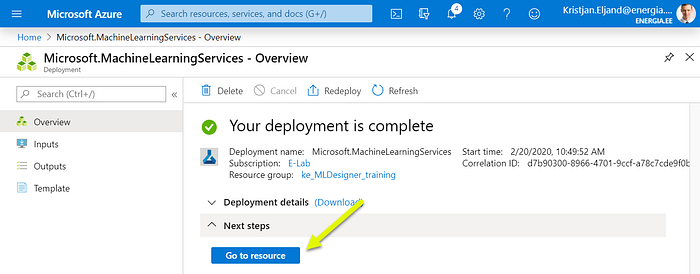
If everything goes as expected, you should see (in 1–2 minutes) that deployment is complete. Click “Go to resource”:
3. Upload the data and enable the computing power
Azure Machine Learning is somewhat complicated to understand because it really isn’t a single service but rather a set of different services. In addition, Microsoft has been changing the ML service a lot so don’t be surprised if the UI looks different while you are reading it. Just recently, Microsoft has created a new Machine learning studio that enables us to carry out the whole workflow.
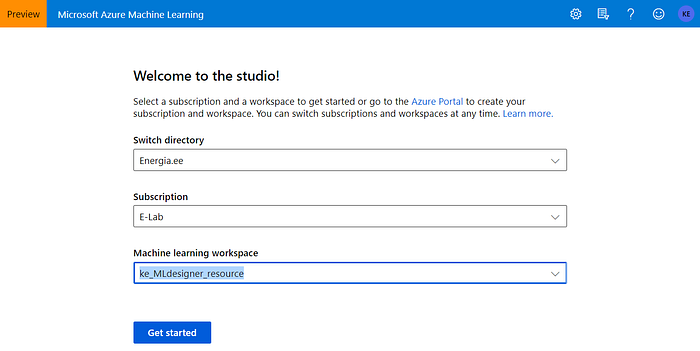
In order to avoid potential problems related to the changes in UI, enter the new machine learning studio through the following link: https://ml.azure.com/ and sign-in with your account.
3.1. Upload the data
First, let’s upload the sample data (download the data, if you haven’t done it yet). Navigate to the Datasets section on the left and click on it:
Click on “Create dataset” -> select “From local files”, give a name to the dataset and click “Next”.
Now, browse the downloaded dataset and click “Next”:
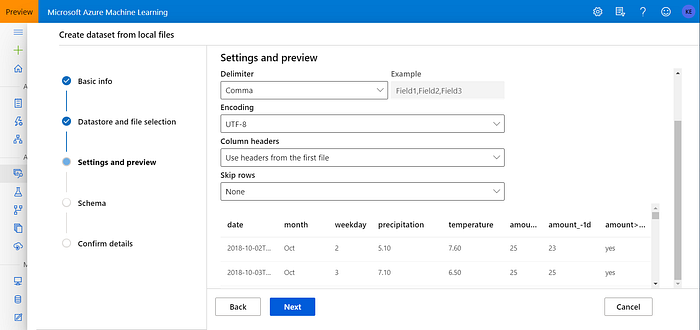
The preview of the dataset opens. If the Column headers selector says, “No headers” then select “Use headers from the first file”. The dataset preview should look like this (notice the bold column names):
The next view enables you to deselect some of the columns if needed. For this exercise, leave everything as is and click next:
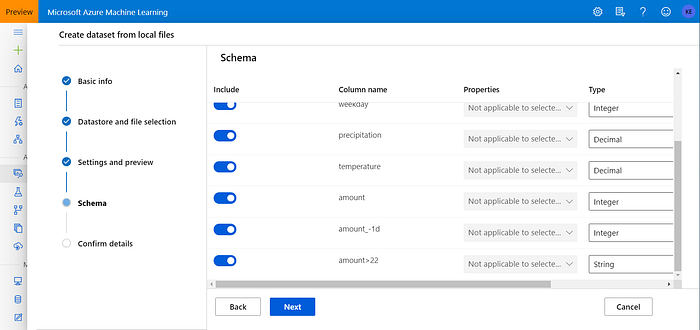
On the last view, click “Confirm” and the dataset will be created. You should be now able to see the dataset under the Registered datasets:
3.2. Create the compute
Right now, we have the dataset, but we haven’t allocated any computing resource to our experiment. If you are used to working with your local computer, then this might seem somewhat odd, but in cloud environments, data, services, and computing power are all well separated.
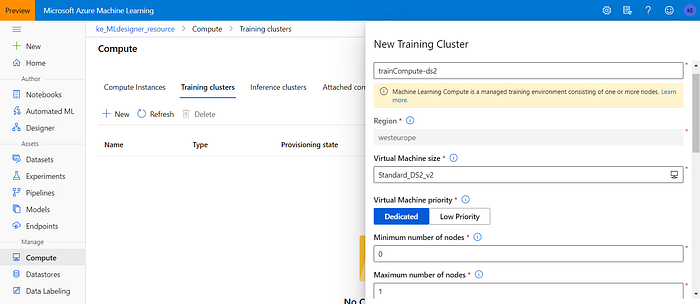
Navigate to “Compute” on the left pane and select “Training clusters”:

Click “New”. You can select amongst a wide variety of different machine sizes. During the recent update, Microsoft has hidden the cost of the resource but you can find it on the pricing page. For our current test:
- Give a name to your compute instance;
- Let’s select DS2 v2, which includes 2 virtual CPUs, 7 GB of RAM and has a cost of €0.14 per hour;
- Set minimum and maximum number of nodes to 1;
- Click “Create” — The creation of the compute cluster might take 1–2 minutes.
4. ML Designer
Now we are ready to start working with Designer. Open it from the left navigation pane and click on + sign to add a new pipeline.

Once opened, the right pane should let you know that No compute target has been selected. Click “Select compute target” and select our freshly created compute instance.

4.1. Preparing the data
On the left navigation pane of the Designer, click on “Datasets” and you should be able to see the uploaded single household consumption data under “My datasets”. To use this data, just drag it to the grey workspace:
4.1.1. Select relevant columns
The aim of our model is to predict whether the daily electricity consumption of the sample households will be larger or smaller than 22 kWh. In our historic data, there is a specific feature “amount>22” for this. Later, we’ll use this feature as a “target” column of our ML model.
Our initial dataset includes some of the columns that we don’t want to use for training. For example, we don’t want to use a specific date, because it will never happen again. Also, we don’t want to include the “amount” feature which reflects the exact electricity consumption on the given day.
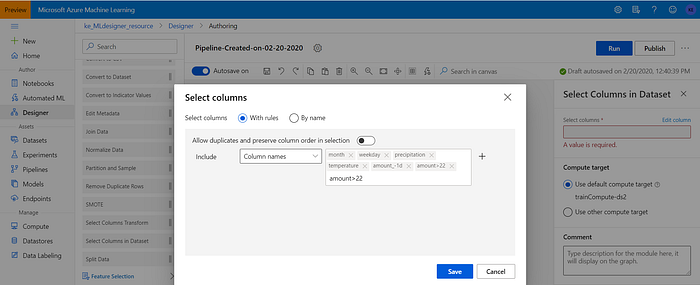
Carry out the column selection as follows:
- Select “Data transformation” on the left navigation pane;
- Find “Select columns” and drag it to the dashboard;
- Connect the “Dataset element” with the “Select columns” element by dragging an arrow between them;
- Select month, weekday, precipitation, temperature, amount_-1d and amount>22;
- Click “Save”.
4.1.2. Splitting the data into train and test datasets
In every ML experiment, data should be split to train and test datasets. The former is needed for model training and the latter for testing the model results. The splitting operation is important to avoid “overfitting” — the situation where the ML model doesn’t learn the general patterns but rather the details of the specific data.
Carry out the splitting as follows:
- Select “Data transformation” on the left navigation pane;
- Find “Split data” and drag it to the dashboard;
- Connect the columns selector element with the split data element;
- Insert 0.8 to the “Fraction of rows in the first output dataset — this means that we’ll be using 80% of the data to train the model and the rest of the data for testing.
- Insert 1234 into the “Random seed” field.
The output should look similar to that below:
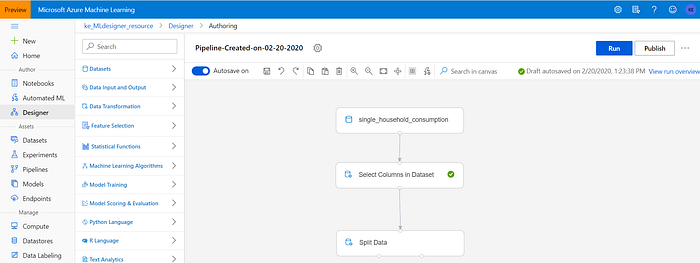
To test, whether the pipeline is working as expected, click on “Run” in the top right part of the page. The “running” operation might take some time but once done, you are able to right-click on elements and visualize the results. For example, the expected result of the “Split Data” element is two datasets.
4.2. Model training
Now we are ready for some model training:
- Select “Machine Learning Algorithms” on the left navigation pane;
- Find “Two-class Boosted Decision Tree” and drag it to the dashboard;
- Select “Model Training” on the left navigation pane;
- Find “Train Model” and drag it to the dashboard;
- Connect the “Decision tree” element and the left-hand side of the “Split Data” element with the “Train model” (picture below).
- Click on the “Train Model” element and select the “amount>22” as a Label column.
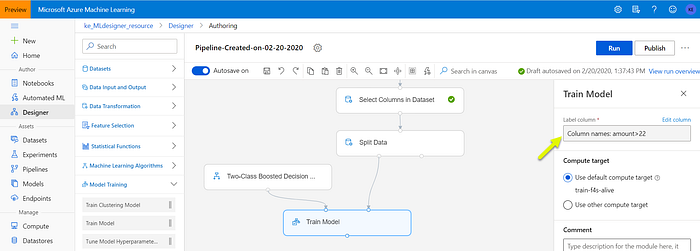
You are ready to train your model: click “Run” on the top-right of the page. If everything goes as expected, your model should be trained with no errors.
4.3. Score and evaluate the model
After you train your model by using 80 percent of the data, you can use the other 20 percent for model evaluation:
- Select “Model Scoring & Evaluation” on the left navigation pane;
- Find the Score Model module and drag it to the dashboard.
- Connect the output of the Train Model module to the left input port of the Score Model. Connect the test data output (right port) of the Split Data module to the right input port of the Score Model.
- Find the Evaluate Model module and drag it to the dashboard.
- Connect the output of the Score Model module to the left input of the Evaluate Model.
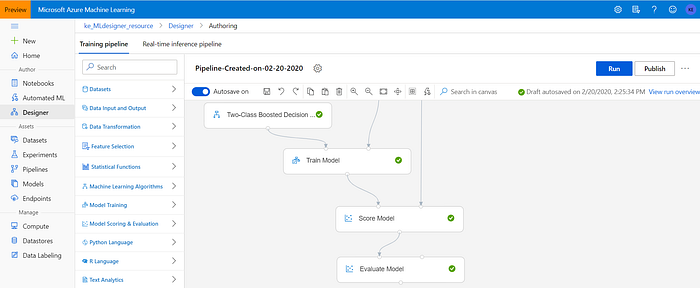
Let’s run the pipeline again (select “Run” on the top-right side of the page). After a successful run, right-click on the “Score Model” module and select “Visualize scored dataset”. This enables you to compare the actual label with the predicted one and see the probability of that score.
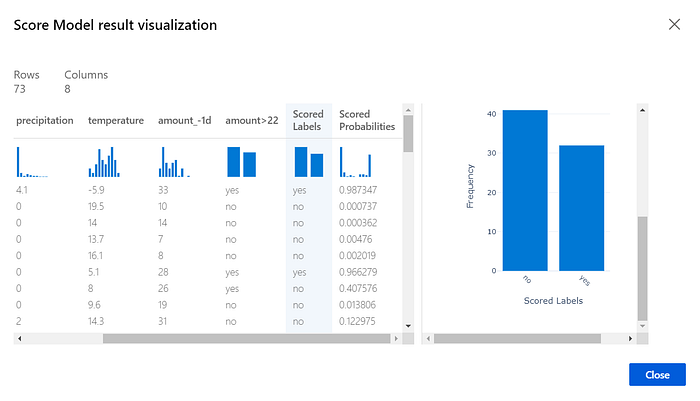
Try the same with the “Evaluation Model” module. Here, you can see the aggregated statistics of the model performance.
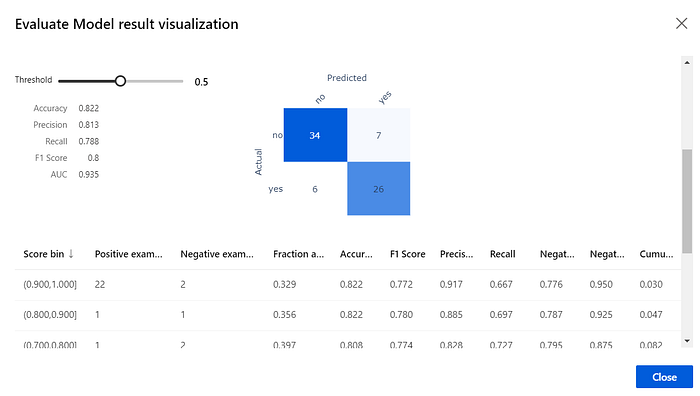
That’s it — now you know the main workflow of training ML models with Azure ML Designer. Next, try to train another model or deploy the existing one by following this tutorial.
